Proof Code® Detector ユーザーガイド
ダウンロード
Proof Code® Detector のホームページからアプリをダウンロードしてください。
http://web16.kazusa.or.jp/software/proofcode/
ダウンロードの際にメールアドレスと所属の入力をお願いしています。
提供された情報の一部を保存しますが、提供コンテンツの充実を目的とした集計で、個人を特定する情報は削除しています。
Proof Code® Detector の動作には事前に cutadapt のインストールが必要となります。
cutadapt のインストールについては Q&A をご参照ください。
http://web16.kazusa.or.jp/software/proofcode/
ダウンロードの際にメールアドレスと所属の入力をお願いしています。
提供された情報の一部を保存しますが、提供コンテンツの充実を目的とした集計で、個人を特定する情報は削除しています。
Proof Code® Detector の動作には事前に cutadapt のインストールが必要となります。
cutadapt のインストールについては Q&A をご参照ください。
インストール
ダブルクリックで圧縮を展開します。
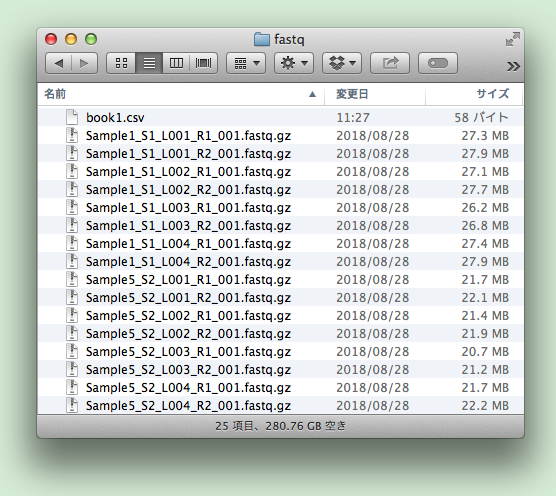
入力ファイルの用意(Illumina シーケンサ出力のフォルダの場合)
入力ファイルはカンマ区切りで「サンプル名」「SpikeIn配列名」となります。
エクセルの場合は保存の際に「CSV(コンマ区切り)(.csv)」を選択してください。
Excel でのデータ作成例:
CSV はテキストファイルで下記のようなものです。
下の例では「book1.csv」の名前で csv 保存しました。
エクセルの場合は保存の際に「CSV(コンマ区切り)(.csv)」を選択してください。
Excel でのデータ作成例:
| A | B | C | D | |
|---|---|---|---|---|
| 1 | Sample1_S1 | In1A01 | ||
| 2 | Sample5_S2 | In1E01 | ||
| 3 | Sample10_S3 | In1A03 |
CSV はテキストファイルで下記のようなものです。
Sample1,In1A01
Sample2,In1E01
Sample3,In1A03
Sample4,In1G02
Sample5,In1C01
Sample2,In1E01
Sample3,In1A03
Sample4,In1G02
Sample5,In1C01
下の例では「book1.csv」の名前で csv 保存しました。
サンプル名の注意
類似しているサンプル名を使わないでください。
プログラムでは、前方一致するシーケンスファイルを全て合算して処理してしまいます。
例:
「sample1」と「sample10」の文字列では、一部に重複がみられます。
これらを混在させてしまった場合、「sample1」の処理では「sample10」のデータも合算して処理してしまいます。
1.sample1_S1_L001_R1_001.fastq.gz
2.sample10_S3_L001_R1_001.fastq.gz ← sample1 のみで判定したいのに sample10 のデータを含んで計算されてしまう
サンプル名を「sample1_S1」と「sample10_S3」などとすれば問題を避けられます。
1.sample1_S1_L001_R1_001.fastq.gz
2.sample10_S3_L001_R1_001.fastq.gz ← ファイル名の重複が解消され、両者を別々に計算
プログラムでは、前方一致するシーケンスファイルを全て合算して処理してしまいます。
例:
「sample1」と「sample10」の文字列では、一部に重複がみられます。
これらを混在させてしまった場合、「sample1」の処理では「sample10」のデータも合算して処理してしまいます。
1.sample1_S1_L001_R1_001.fastq.gz
2.sample10_S3_L001_R1_001.fastq.gz ← sample1 のみで判定したいのに sample10 のデータを含んで計算されてしまう
サンプル名を「sample1_S1」と「sample10_S3」などとすれば問題を避けられます。
1.sample1_S1_L001_R1_001.fastq.gz
2.sample10_S3_L001_R1_001.fastq.gz ← ファイル名の重複が解消され、両者を別々に計算
アプリの実行
「book1.csv」を「Proof Code® Detector」にドラッグ&ドロップします。
アプリの起動と解析開始
「book1.csv」を「Proof Code® Detector」にドラッグ&ドロップします。
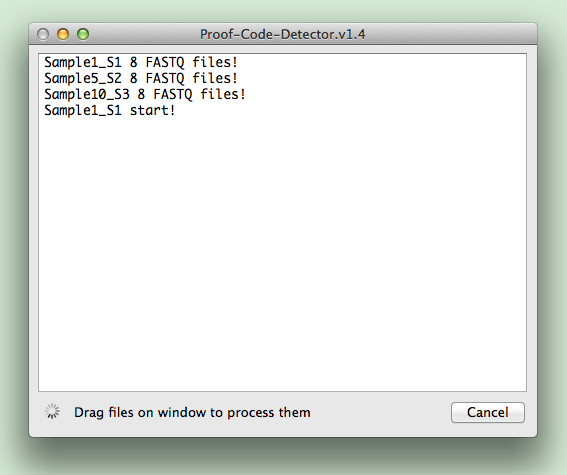
解析の完了
完了したら右下の「Quit」を押してアプリを終了します。
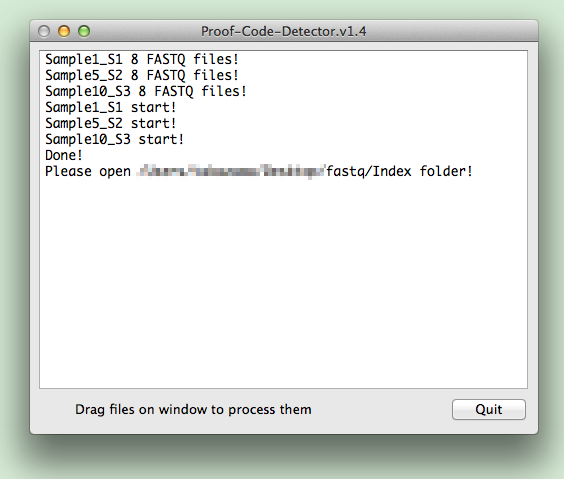
解析結果
ランフォルダ内に解析結果 Results.txt が出力されます。
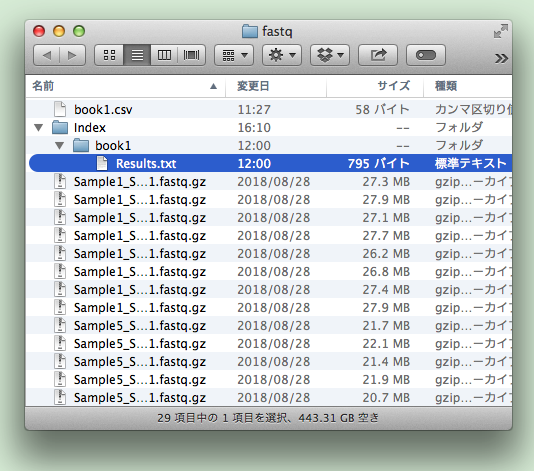
出力例:
クロスコンタミネーションが検出されなかった場合
解析結果 図表化
クロスコンタミネーションが検出された場合
解析結果 図表化
出力例:
クロスコンタミネーションが検出されなかった場合
解析結果 図表化
クロスコンタミネーションが検出された場合
解析結果 図表化
解析結果の図表化
Proof Code® Detector ホームページにて Results.txt の図表化を行うことが出来ます。
Results.txt を選択して「ビジュアライズ実行」をクリックしてください。
処理が終わると画面に PDF ファイルへのリンクが表示されます。
PDF はご利用のブラウザまたはリンク先の保存等でダウンロードしてご覧いただけます。
Results.txt を選択して「ビジュアライズ実行」をクリックしてください。
処理が終わると画面に PDF ファイルへのリンクが表示されます。
PDF はご利用のブラウザまたはリンク先の保存等でダウンロードしてご覧いただけます。